
Table of Contents
In this tutorial, I will take you through 10 Popular Kafka Console Producer and Consumer Examples. Kafka is currently in high demand due to its various use cases. It is widely used as a messaging system, as a storage system and for stream processing. Kafka usually consists of four API Producer API, Consumer API, Streams API and Connector API. Here we will discuss about the Usage of Producer API and Consumer API in Kafka Console Producer and Kafka Console Consumer.
Introduction to Kafka Console Producer
Kafka Console Producer publishes data to the subscribed topics. Data will generally be regarded as records which gets published in the Topic partition in a round robin fashion. An application generally uses Producer API to publish streams of record in multiple topics distributed across the Kafka Cluster. Kafka Cluster contains multiple nodes and each nodes contains one or more topics.
As per Kafka Official Documentation, The Kafka cluster durably persists all published records whether or not they have been consumed using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
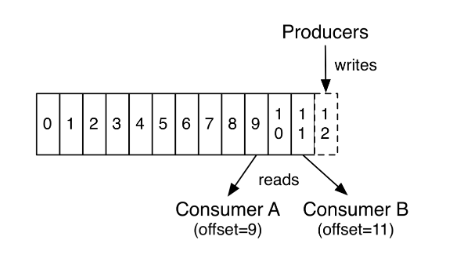
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
Introduction to Kafka Console Consumer
Kafka Console Consumer generally belongs to Consumer group. It is responsible for reading the data from subscribed topics where data gets published by the producer processes. An application usually utilizes Consumer API to subscribe to one or more topics for stream processing.
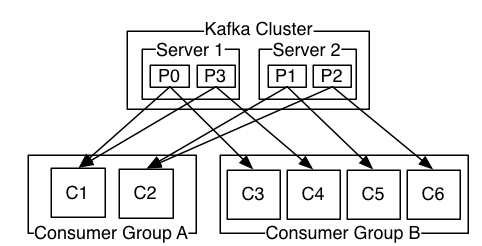
Let's understand consumer through above architecture. A two server Kafka cluster hosting four partitions (P0-P3) with two consumer groups. Consumer group A has two consumer instances and group B has four.
More commonly, however, we have found that topics have a small number of consumer groups, one for each "logical subscriber". Each group is composed of many consumer instances for scalability and fault tolerance. This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.
You can also check below topics to know more about Kafka:-
Popular Apache Kafka Architecture explained using 4 basic components
17 Useful Apache Kafka Examples on Linux(RedHat/CentOS 7/8)
How to Install Apache Kafka on Ubuntu 18.04
How to Install Apache Zookeeper on Ubuntu 18.04

Kafka Console Producer
Also Read: Explaining Apache Kafka Architecture in 3 Easy Steps
Step 1: Prerequisites
a)You need to have a running Linux Based System.
b)You should have wget tool installed in your system.
c)You should have privilege user account access to run all the commands.
NOTE:
sudo access to perform below steps. You can check Step by Step: How to add User to Sudoers to provide sudo access to user.Step 2: Download Kafka
You can download Apache Kafka from Official Download Page using wget command as shown below.
[root@localhost ~]# wget https://downloads.apache.org/kafka/2.4.1/kafka_2.13-2.4.1.tgz --2020-04-02 19:25:46-- https://downloads.apache.org/kafka/2.4.1/kafka_2.13-2.4.1.tgz Resolving downloads.apache.org (downloads.apache.org)... 88.99.95.219, 2a01:4f8:10a:201a::2 Connecting to downloads.apache.org (downloads.apache.org)|88.99.95.219|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 62127579 (59M) [application/x-gzip] Saving to: ‘kafka_2.13-2.4.1.tgz’ 100%[==============================================================================================================================>] 62,127,579 2.72MB/s in 22s 2020-04-02 19:26:09 (2.65 MB/s) - ‘kafka_2.13-2.4.1.tgz’ saved [62127579/62127579]
Step 3: Extract Kafka Tar File
Now you can extract the Kafka Tar Package into same directory or any other directory you want to keep the binaries files using tar -xvf kafka_2.13-2.4.1.tgz command as shown below.
[root@localhost ~]# tar -xvf kafka_2.13-2.4.1.tgz kafka_2.13-2.4.1/ kafka_2.13-2.4.1/LICENSE kafka_2.13-2.4.1/NOTICE kafka_2.13-2.4.1/bin/ kafka_2.13-2.4.1/bin/kafka-delete-records.sh kafka_2.13-2.4.1/bin/trogdor.sh kafka_2.13-2.4.1/bin/kafka-preferred-replica-election.sh kafka_2.13-2.4.1/bin/connect-mirror-maker.sh kafka_2.13-2.4.1/bin/kafka-console-consumer.sh kafka_2.13-2.4.1/bin/kafka-consumer-perf-test.sh kafka_2.13-2.4.1/bin/kafka-log-dirs.sh kafka_2.13-2.4.1/bin/zookeeper-server-stop.sh kafka_2.13-2.4.1/bin/kafka-verifiable-consumer.sh kafka_2.13-2.4.1/bin/kafka-acls.sh kafka_2.13-2.4.1/bin/zookeeper-server-start.sh kafka_2.13-2.4.1/bin/kafka-server-stop.sh kafka_2.13-2.4.1/bin/kafka-configs.sh kafka_2.13-2.4.1/bin/kafka-reassign-partitions.sh
Step 4: Start Zookeeper Cluster
First, you need to start the Zookeeper Cluster before starting Kafka Service using zookeeper-server-start.sh script as shown below.
[root@localhost kafka_2.13-2.4.1]# bin/zookeeper-server-start.sh config/zookeeper.properties [2020-04-03 09:42:37,086] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,089] WARN config/zookeeper.properties is relative. Prepend ./ to indicate that you're sure! (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,113] INFO clientPortAddress is 0.0.0.0:2181 (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,114] INFO secureClientPort is not set (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,118] INFO autopurge.snapRetainCount set to 3 (org.apache.zookeeper.server.DatadirCleanupManager) [2020-04-03 09:42:37,118] INFO autopurge.purgeInterval set to 0 (org.apache.zookeeper.server.DatadirCleanupManager) [2020-04-03 09:42:37,119] INFO Purge Kafka Console Producer. (org.apache.zookeeper.server.DatadirCleanupManager) [2020-04-03 09:42:37,119] WARN Kafka Console Producer defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain) [2020-04-03 09:42:37,121] INFO Log4j found with jmx enabled. (org.apache.zookeeper.jmx.ManagedUtil) [2020-04-03 09:42:37,170] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,171] WARN config/zookeeper.properties is relative. Prepend ./ to indicate that you're sure! (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,171] INFO clientPortAddress is 0.0.0.0:2181 (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,172] INFO secureClientPort is not set (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2020-04-03 09:42:37,172] INFO Starting server (org.apache.zookeeper.server.ZooKeeperServerMain) [2020-04-03 09:42:37,178] INFO zookeeper.snapshot.trust.empty : false (org.apache.zookeeper.server.persistence.FileTxnSnapLog) [2020-04-03 09:42:37,202] INFO Server environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT (org.apache.zookeeper.server.ZooKeeperServer)
Step 5: Start Kafka Cluster
As you know Kafka Cluster is a distributed systems of Kafka Broker which is managed by Zookeeper Server so you need to start Kafka Cluster Service in order to connect it to Zookeeper. Zookeeper will be responsible for managing Kafka Broker which in turn responsible for managing messages queues between Producer and Consumer.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-server-start.sh config/server.properties [2020-04-03 09:43:38,780] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$) [2020-04-03 09:43:40,603] INFO Registered signal handlers for TERM, INT, HUP (org.apache.kafka.common.utils.LoggingSignalHandler) [2020-04-03 09:43:40,604] INFO starting (kafka.server.KafkaServer) [2020-04-03 09:43:40,606] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer) [2020-04-03 09:43:40,678] INFO [ZooKeeperClient Kafka server] Initializing a new session to localhost:2181. (kafka.zookeeper.ZooKeeperClient) [2020-04-03 09:43:40,691] INFO Client environment:zookeeper.version=3.5.7-f0fdd52973d373ffd9c86b81d99842dc2c7f660e, built on 02/10/2020 11:30 GMT (org.apache.zookeeper.ZooKeeper) [2020-04-03 09:43:40,694] INFO Client environment:host.name=localhost (org.apache.zookeeper.ZooKeeper) [2020-04-03 09:43:40,695] INFO Client environment:java.version=1.8.0_242 (org.apache.zookeeper.ZooKeeper) [2020-04-03 09:43:40,695] INFO Client environment:java.vendor=Oracle Corporation (org.apache.zookeeper.ZooKeeper) [2020-04-03 09:43:40,695] INFO Client environment:java.home=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre (org.apache.zookeeper.ZooKeeper)
Step 6: Kafka Create Topic
It is important to create a topic so that producer can subscribe this topic to publish its messages. A topic consists of multiple partitions and resides on Kafka Broker. Here we will create a topic testTopic1 with single partition. You can also add partition later if you want to.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic1 Created topic testTopic1.
Step 7: Start Kafka Console Producer
Now you can start the Kafka Console producer to send your messages using Kafka Topics you have created above.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic1
Step 8: Start Kafka Console Consumer
After starting Kafka Console Producer, you need to start Kafka Console Consumer service to consume messages from the queue where Kafka Console producer published the messages.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic1 --from-beginning
Step 9: Start Sending Message through Kafka Console Producer
Once Kafka Console Producer is started and ready you can start sending messages as below.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic1 >This is hello from CyberITHub >
Step 10: Receive Message through Kafka Console Consumer
Simultaneously you can check producer messages getting consumed by the Kafka console consumer service and displayed it on Console Output as shown below.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic1 --from-beginning This is hello from CyberITHub
I hope that you liked this tutorial on Kafka Console Producer and Kafka Console Consumer examples. Please provide your feedback on Comment Box.