
Table of Contents
In this tutorial, I will explain about Apache Kafka Architecture in 3 Popular Steps. Kafka was released as an open source project on GitHub in late 2010. As it started to gain attention in the open source community, it was proposed and accepted as an Apache Software Foundation incubator project in July of 2011. Apache Kafka graduated from the incubator in October of 2012. Since then, it has continuously been worked on and has found a robust community of contributors and committers outside of LinkedIn.

Kafka is now used in some of the largest data pipelines in the world. In the fall of 2014, Jay Kreps, Neha Narkhede, and Jun Rao left LinkedIn to found Confluent, a company centered around providing development, enterprise support, and training for Apache Kafka. The two companies, along with ever-growing contributions from others in the open source community, continue to develop and maintain Kafka, making it the first choice for big data pipelines.
Apache Kafka Architecture Diagram
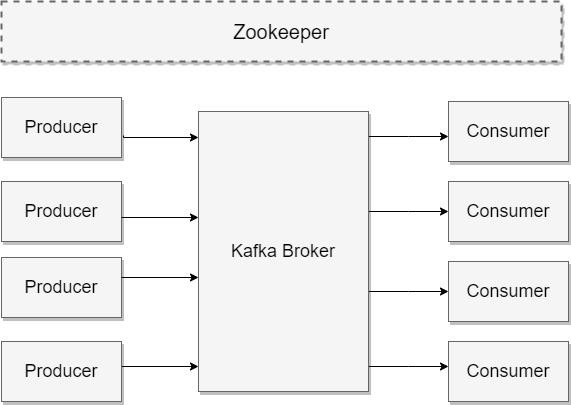
A typical Kafka cluster consists of multiple brokers. It helps in load-balancing message reads and writes to the cluster. Each of these brokers is stateless. However, they use Zookeeper to maintain their states. Each topic partition has one of the brokers as a leader and zero or more brokers as followers. The leaders manage any read or write requests for their respective partitions. Followers replicate the leader in the background without actively interfering with the leader's working. You should think of followers as a backup for the leader and one of those followers will be chosen as the leader in the case of leader failure.
Kafka Basics Workflow
Also Read: 10 Popular Kafka Console Producer and Consumer Examples
Every message in Kafka topics is a collection of bytes. This collection is represented as an array. Producers are the applications that store information in Kafka queues. They send messages to Kafka topics that can store all types of messages. Every topic is further differentiated into partitions. Each partition stores messages in the sequence in which they arrive.
There are two major operations that producers/consumers can perform in Kafka. Producers append to the end of the write-ahead log files. Consumers fetch messages from these log files belonging to a given topic partition. Physically, each topic is spread over different Kafka brokers, which host one or two partitions of each topic.
Apache Kafka Producer
Kafka can be used as a message queue, message bus, or data storage system. Irrespective of how Kafka is used in your enterprise, you will need an application system that can write data to the Kafka cluster. Such a system is called a producer. As the name suggests, they are the source or producers of messages for Kafka topics. Kafka producers publish messages as per Kafka protocols defined by the makers of Kafka.
Apache Kafka Consumer
Consumer operations start with subscribing to a topic. If consumer is part of a consumer group, it will be assigned a subset of partitions from that topic. Consumer process would eventually read data from those assigned partitions. You can think of topic subscription as a registration process to read data from topic partitions.
Zookeeper
Zookeeper is an important component of a Kafka cluster and plays an important role in Apache Kafka Architecture. It manages and coordinates Kafka brokers and consumers. Zookeeper keeps track of any new broker additions or any existing broker failures in the Kafka cluster.
Accordingly, it will notify the producer or consumers of Kafka queues about the cluster state. This helps both producers and consumers in coordinating work with active brokers. Zookeeper also records which broker is the leader for which topic partition and passes on this information to the producer or consumer to read and write the messages.
Schemas
While messages are opaque byte arrays to Kafka itself, it is recommended that additional structure, or schema, be imposed on the message content so that it can be easily understood. There are many options available for message schema, depending on your application’s individual needs. Simplistic systems, such as Javascript Object Notation (JSON) and Extensible Markup Language (XML), are easy to use and human-readable.
However, they lack features such as robust type handling and compatibility between schema versions. Many Kafka developers favor the use of Apache Avro in Apache Kafka Architecture, which is a serialization framework originally developed for Hadoop. Avro provides a compact serialization format; schemas that are separate from the message payloads and that do not require code to be generated when they change; and strong data typing and schema evolution, with both backward and forward compatibility.
Apache Avro
Apache Avro is a language-neutral data serialization format. The project was created by Doug Cutting to provide a way to share data files with a large audience. Apache Avro plays a crucial role in Kafka Architecture.
Avro data is described in a language-independent schema. The schema is usually described in JSON and the serialization is usually to binary files, although serializing to JSON is also supported. Avro assumes that the schema is present when reading and writing files, usually by embedding the schema in the files themselves.
One of the most interesting features of Avro, and what makes it a good fit for use in a messaging system like in Apache Kafka Architecture, is that when the application that is writing messages switches to a new schema, the applications reading the data can continue processing messages without requiring any change or update.
Kafka Stream
The term stream is often used when discussing data within systems like Kafka. Most often, a stream is considered to be a single topic of data, regardless of the number of partitions. This represents a single stream of data moving from the producers to the consumers. This way of referring to messages is most common when discussing stream processing, which is when frameworks—some of which are Kafka Streams, Apache Samza, and Storm—operate on the messages in real time. This method of operation can be compared to the way offline frameworks, namely Hadoop, are designed to work on bulk data at a later time.
Also Read: Kafka: The Definitive Guide
Reference: Building Data Streaming Applications with Apache Kafka