
Table of Contents
In this article, I will go through Apache Kafka tutorial from beginners perspective so that anyone learning Kafka for the first time can understand it. To understand Kafka you need to first understand why we need Kafka ? Any application which is dealing with lot of upstream and downstream data requires almost zero time lag so that it will be available quickly as and when required by an application components. This demand is perfectly fulfilled by Apache Kafka. It provides real time streams of data and basically works on publish-subscribe messaging System.

Apache Kafka Tutorial for Beginners
Also Read: How to Install MariaDB 5.5 Server on RHEL/CentOS 7 Linux with Easy Steps
Kafka Introduction
A good place to start is with the amount of data retention required, followed by the performance needed from the producers. If very low latency is necessary, I/O optimized instances that have local SSD storage might be required. Otherwise, remote storage (such as the AWS Elastic Block Store) might be sufficient. Once these decisions are made, the CPU and memory options available will be appropriate for the performance.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-topics.sh --version
2.4.1 (Commit:c57222ae8cd7866b)
Kafka Architecture Diagram
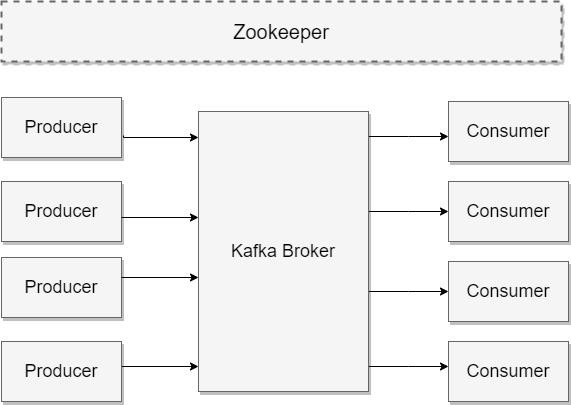
Apache Kafka Benefits
The biggest benefit is the ability to scale the load across multiple servers. A close second is using replication to guard against data loss due to single system failures. Replication will also allow for performing maintenance work on Kafka or the underlying systems while still maintaining availability for clients.
Kafka Topics and Partitions
Messages in Kafka are categorized into topics. The closest analogies for a topic are a database table or a folder in a filesystem. Topics are additionally broken down into a number of partitions. Going back to the “commit log” description, a partition is a single log. Messages are written to it in an append-only fashion, and are read in order from beginning to end. Note that as a topic typically has multiple partitions, there is no guarantee of message time-ordering across the entire topic, just within a single partition.
Kafka Producer
Producers create new messages. In other publish/subscribe systems, these may be called publishers or writers. In general, a message will be produced to a specific topic. By default, the producer does not care what partition a specific message is written to and will balance messages over all partitions of a topic evenly. In some cases, the producer will direct messages to specific partitions. This is typically done using the message key and a partitioner that will generate a hash of the key and map it to a specific partition. This assures that all messages produced with a given key will get written to the same partition. The producer could also use a custom partitioner that follows other business rules for mapping messages to partitions.
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic1
>This is hello from CyberITHub
>
Kafka Consumer
Consumers read messages. In other publish/subscribe systems, these clients may be called subscribers or readers. The consumer subscribes to one or more topics and reads the messages in the order in which they were produced. The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages. The offset is another bit of metadata—an integer value that continually increases—that Kafka adds to each message as it is produced. Each message in a given partition has a unique offset. By storing the offset of the last consumed message for each partition, either in Zookeeper or in Kafka itself, a consumer can stop and restart without losing its place. More on Kafka: The Definitive Guide
[root@localhost kafka_2.13-2.4.1]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic1 --from-beginning
This is hello from CyberITHub
Apache Kafka Broker
A single Kafka server is called a broker. The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk. It also services consumers, responding to fetch requests for partitions and responding with the messages that have been committed to disk. Depending on the specific hardware and its performance characteristics, a single broker can easily handle thousands of partitions and millions of messages per second.
Popular Recommendations:-
Solved: ModuleNotFoundError: No module named 'requests' in Python 3
How to Properly Search PHP Modules Using YUM tool in Linux(RHEL/CentOS 7/8)
How to Install and Configure Squid Proxy Server on RHEL/CentOS 7/8
Primitive Data Types in Java - int, char, byte, short, long, float, double and boolean
5 Best Ways to Become root user or Superuser in Linux (RHEL/CentOS/Ubuntu)